

In the previous blog post we have talked about basic principles of building AI assistants. Let’s take them for a spin with a product case that we’ve worked on: using AI to support enterprise sales pipelines.
B2B sales in the enterprise world are very lucrative, once they go through. However, they can take years to settle. This means, that a company needs to have multiple leads in the sales pipeline at once. This is a resource-intensive process that is frequently limited by a human factor; sales become the bottleneck.
It is possible to remove the bottleneck from sales if we could:
increase the number of cases a single sales representative can push through at a given time
prioritise high-quality leads with a higher success probability
One project that we have worked on, aims to do exactly that. It is an AI assistant that ingests publicly available information about large companies: Annual Reports, SEC Filings or ESMA documents. This is a large set of data, potentially filled with really good leads.
We just need to sift through that data, finding information about companies and prioritising cases according to our unique sales process. How hard can that be?
Exploring hallucinations of AI assistants
As it turns out, classical vector-based AI RAG systems fail even at the most simple sales question: “Which company has the most cash available right now?”
In theory, getting this answer from an annual sales report is as easy as looking for the “Cash” entry in the “consolidated balance sheet”.
As you can see in our Enterprise AI Leaderboard section (from the February LLM Benchmark) even the best document retrieval systems sometimes fail to answer questions about a single annual report:
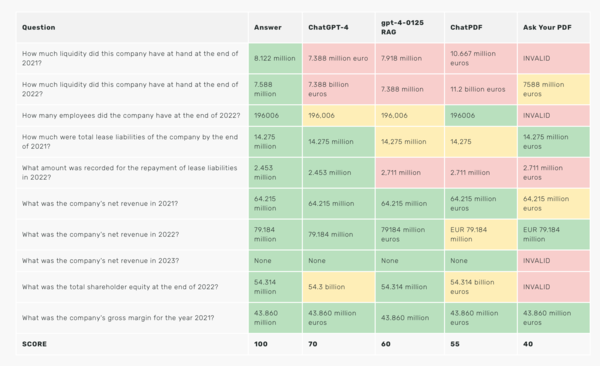
Things get substantially worse, if you would try to upload multiple annual reports and ask “Which company has the most cash”.
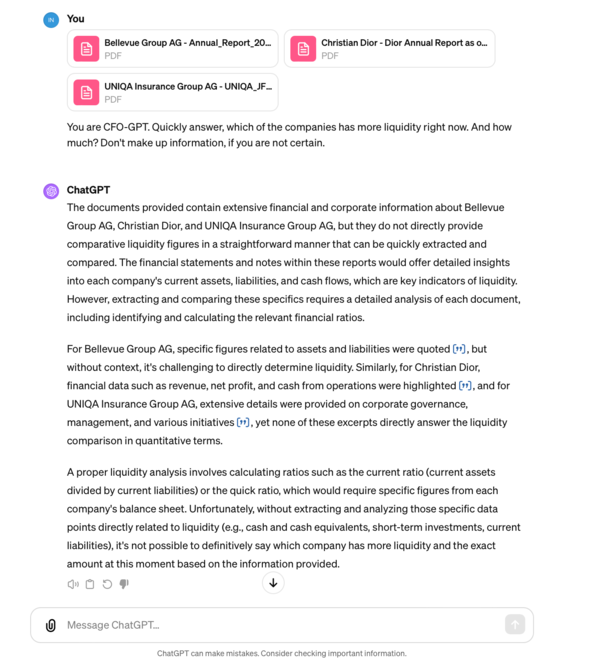
Here is an experiment you can reproduce with an AI assistant of your choice:
Get annual reports for 2022 from Christian Dior, Bellevue Group and UNIQA Insurance Group (or any other combination for that matter)
Upload these to a RAG
Ask a very specific question:


















































































: Integation von KI-Prozesse")











