

Miro is an online collaborative whiteboard platform which we are using heavily in our consulting workshops to collaborate, explore and document. In this blog post I will show you options to automatically gather, modify and analyse Miro boards.
Why we wanted to gather data from miro
In one of our Innovation Incubator rounds, the idea was born to find ways to analyse Big Picture Event storms and their evolution over time in the course of the workshop’s post processing. Wouldn’t it be helpful if you could create a replay cockpit where you can replay the whole workshop and see how this event storm evolved over time.
Additionally we needed to export board data into our statistical analyzers written in python. Basic data such as stickers and their history needed to generate word clouds, lingual analysis and activity analysis of workshop participants.
So the idea was born to check out the Miro Options to gather data and create ideas how this data can be analysed.
Options to access Miro Data
MIRO provides two ways of accessing data. You can either use the Miro REST API or the Miro Web Plugin SDK. The REST API provides easy access to basic board data but it is not yet comprehensive whereas the Miro SDK provides more capabilities.
Retrieving Data
The REST API is the simplest way to retrieve data from Miro. The following preparatory steps need to be executed to access the API (detailed description can be found here)
1. Create a developer team
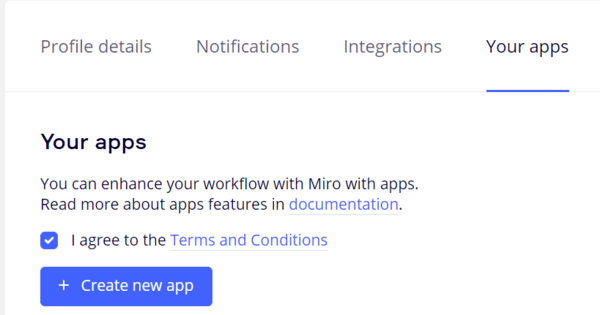
2. Create an APP within your organization. Go to your User->Profile Settings->Your Apps
3. Create a developer team
4. Create an APP within your organization: Go to your User->Profile Settings —> Your Apps
Once you have gathered you personal access (bearer) token, the first request can be sent to Miro on behalf of your Miro user. You can access any resource your Miro user has access to, limited by the app permission scope (intersection of both permissions). It is also possible to send requests on behalf other users, however this requires that you set up an OAUTH 2.0 flow. In this Python sample request we retrieve all widgets from a board.










































































: Integation von KI-Prozesse")

























