

When browsing the web, numerous posts can be found discussing techniques to speed up the training time of well-known machine learning algorithms. Surprisingly, there is limited information available regarding the prediction phase. However, from a practical standpoint, this aspect holds great relevance. Once a satisfactory regression algorithm has been trained, it is typically deployed in a real-world system. In such cases, the speed at which predictions are obtained becomes crucial. Faster prediction times enable real-time or near-real-time decision-making, enhance user experience in interactive applications, and facilitate efficient processing of large-scale datasets. Therefore, optimizing inference speed can have significant implications for various domains and applications.
The purpose of this blog post is to investigate the performance and prediction speed behavior of popular regression algorithms, i.e. models that predict numerical values based on a set of input variables. Considering that scikit-learn is the most extensively utilized machine learning framework [1], our focus will be on exploring methods to accelerate its algorithms' predictions.
Benchmarking regression algorithms
To assess the current state of popular regression algorithms, we selected four popular regression datasets from Kaggle [2], along with an internal dataset from our company. These datasets vary in sample size, number and type of features, capturing performance for different data structures.
To ensure fair comparisons, we need to optimize hyperparameters before testing to unlock the models' full potential. We will benchmark the following regression algorithms:
The different versions of regularized linear regression, such as lasso, ridge, and elastic net, are not analyzed separately as they were comparable to pure linear regression in terms of prediction speed and accuracy in a pre-evaluation step.
Prediction speed vs. accuracy
The plot below displays the benchmarking results on our company's internal dataset. We can observe a sweet spot in the bottom left, where both the error - measured via root mean square error (RMSE) - and prediction times are low. Simple neural networks (Multilayer Perceptron, MLP) and gradient boosted regression trees demonstrate good performance in both dimensions. Random forest also shows decent accuracy but has the highest prediction time. Other algorithms exhibit reasonable prediction speed but relatively high errors.
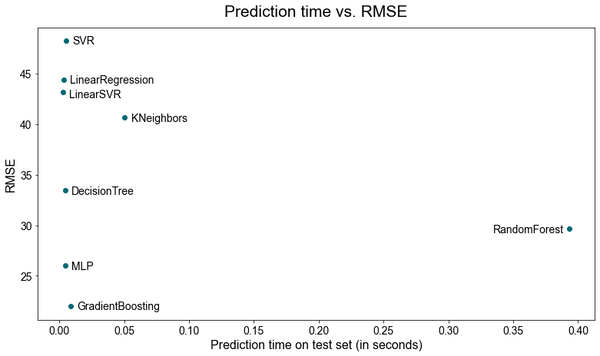
However, it is crucial to try different algorithms on the specific dataset at hand. Accuracy and prediction time heavily depend on the number of features used, their transformations, as well as the model's parameters. Linear models, for example, may perform well with properly transformed features, while larger MLPs might exhibit longer prediction times. Nevertheless, algorithms like random forest and k-NN are by construction expected to be slower in inference speed.
How to speed up inference
Generally, scikit-learn models are already optimized through compiled Cython extensions or optimized computing libraries [3]. However, there are additional ways to accelerate prediction latency, apart from using faster hardware. In this blog post, we’ll benchmark the following optimizations:
Data-based approaches:
Reduce the number of features by selecting relevant ones or applying dimensionality reduction (“Half features”)
Implementation-based approaches:
Apply bulk prediction instead of atomic prediction, enabling parallelization and speeding up the process (“Bulk 100/1000”)
Utilize the Intel extension for scikit-learn, which supports certain algorithms and can lead to significant speed improvements (“Intel extension”)
Disable scikit-learn's validation overhead, which checks the finiteness of the data (“No finite check”)
Furthermore, we want to mention the following optimization approaches, which we did not include in our benchmark, partly because they are problem specific:
Data-based approaches:
Efficiently represent input data, such as using sparse matrix data structures
Optimize feature extraction and transformation, including efficient database queries and preprocessing tasks
Model-based approaches:
Reduce the complexity of the model, such as reducing the size of a random forest or MLP architecture
Utilize model-specific accelerators
Implementation-based approaches:
Implement the prediction step with given weights independently, potentially in a faster programming language, to avoid unnecessary overhead
Use cloud services for prediction, such as Google ML, Amazon ML or MS Azure
As you can see, there are numerous ways to influence inference time, ranging from fundamental approaches to simple tricks. Changing the data structure and implementing algorithms from scratch optimized for efficiency may be more involved, while the latter approaches can be easily applied even to existing systems that use scikit-learn.
Note that all of the above approaches do not affect prediction quality, except reducing the number of features and model complexity. For these approaches, it is important to evaluate the trade-off between prediction speed and quality.
In this blog post, we mostly benchmark approaches that do not affect prediction quality, and therefore focus on evaluating the speedup in the next section.
Evaluating some speedup tricks
Check out the technical appendix to see how the time measurement is performed.
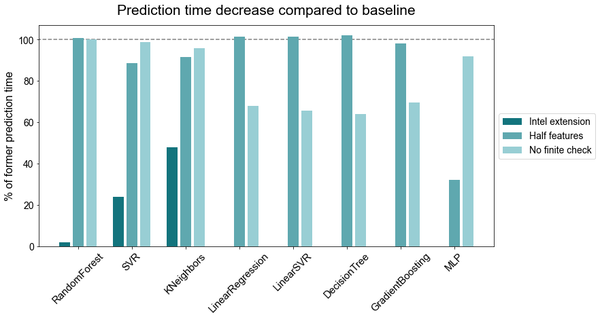
Reducing the number of features by half (in our case from 106 to 53 features) only leads to small decreases in inference speed for KNN, SVR while it had an major influence on the MLP. Disabling scikit-learn's finiteness checkup, which is just one line of code, improves prediction speed more significantly. As can be seen below, inference time can be reduced up to 40% depending on the algorithm. Utilizing the Intel extension for scikit-learn, also requiring only one line of code, results in substantial speed improvements for random forest, SVR and the KNN regressor. For the latter two algorithms, a time reduction of more than 50% could be achieved, while for random forest, prediction time decreases by impressive 98%. In the plots below there are no values shown for the other algorithms as the Intel extension currently does not support those.
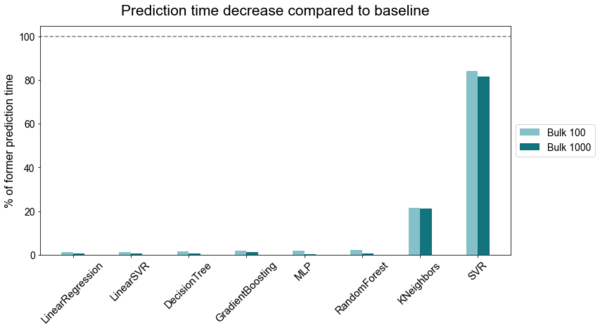
As can be seen below, most potential lies in bulk inference. By predicting several samples simultaneously (here: 100 or 1000 samples at once), the average prediction time per sample decreases significantly for most of the algorithms. Overall, bulk prediction can lead up to 200-fold speed increases in this test setting. This approach is particularly effective for the MLP as well as linear and tree based methods, greatly accelerating their performance.
Summary
Fast predictions are crucial for various use cases, in particular when it comes to real-time predictions. Moreover, investing in efficiency always pays off by reducing energy consumption, thus saving money and at the same time lowering carbon emissions.
In this blog post we have explored multiple ways to achieve faster prediction times. Firstly, the dimensionality of the data and the algorithm chosen have major influence on inference speed and scalability behaviour. However, there are various tricks to even accelerate existing scikit-learn code. Disabling scikit-learn's finite data validation or utilizing the Intel extension for supported algorithms can already yield considerable improvements depending on the algorithm. However, the most substantial gains can be achieved by addressing fundamental aspects, such as reducing the number of features (in particular for high-dimensional data), implementing bulk prediction or custom prediction methods. These strategies can result in speed increases by factors of several hundred.
In our small test setting, we could additionally show that a small neural network, gradient boosted regressor and random forest appear to be the most promising choices in terms of both accuracy and speed, when using the above-mentioned speedup tricks.
Sources
[2] House sales: House Sales in King County, USA ,
red wine quality: Red Wine Quality ,
avocado prices: Avocado Prices ,
medical insurance costs: Medical Cost Personal Datasets
[3] 8. Computing with scikit-learn — scikit-learn 0.23.2 documentation
Technical Appendix
Speedtests were performed with all unnecessary background processes stopped.
Inference time measurement for one test sample (“atomic prediction”):









: Integation von KI-Prozesse")








































































