In part 3 of this blog series, we'll explore the proper usage of data analysis with ChatGPT-3.5 and how you can analyze and visualize data from a SQLite database to help you make the most of your data.
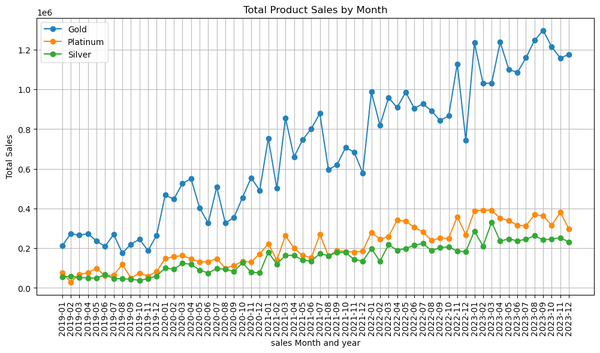
Suppose we have a database file for a gold broker company that sells gold and we want to analyze the total monthly sales for each product. What do we do and what is the logical question to understand that gold.db?
Tools You Will Need
The first step
Open the gold.db file in the database browser (SQLite DB Browser) and copy the database schema information:
-
CREATE TABLE Customer ( CustomerID INTEGER PRIMARY KEY AUTOINCREMENT, FirstName TEXT, LastName TEXT, Email TEXT, Phone TEXT, Address TEXT, RegistrationDate DATE );
-
CREATE TABLE OrderDetails ( OrderDetailID INTEGER PRIMARY KEY AUTOINCREMENT, OrderID INTEGER, ProductID INTEGER, Quantity INTEGER, PriceAtTimeOfPurchase REAL, FOREIGN KEY (OrderID) REFERENCES Orders(OrderID);
-
Updated reference FOREIGN KEY (ProductID) REFERENCES Product(ProductID) ); CREATE TABLE Orders ( OrderID INTEGER PRIMARY KEY AUTOINCREMENT, CustomerID INTEGER, OrderDate DATE, Status TEXT, FOREIGN KEY (CustomerID);
-
REFERENCES Customer(CustomerID) ); CREATE TABLE Product ( ProductID INTEGER PRIMARY KEY AUTOINCREMENT, ProductName TEXT, MetalType TEXT, Form TEXT, Weight REAL, Purity REAL, StockQuantity INTEGER, PricePerUnit REAL );
-
CREATE TABLE Supplier ( SupplierID INTEGER PRIMARY KEY AUTOINCREMENT, SupplierName TEXT, Contact TEXT, Email TEXT, Phone TEXT ); CREATE TABLE Supply ( SupplyID INTEGER PRIMARY KEY AUTOINCREMENT, SupplierID INTEGER, ProductID INTEGER, SupplyDate DATE, Quantity INTEGER, PricePerUnit REAL, FOREIGN KEY (SupplierID) REFERENCES Supplier(SupplierID), FOREIGN KEY (ProductID) REFERENCES Product(ProductID);
The second step
Write the following question in ChatGPT!
You are a data engineer and have a sqlite3 database with the following schema. You should write a python script that you can run in a Jupyter Notebook that should draw a diagram. The data in the database comes from sales of a gold broker company. Build a chart that shows total sales of products by month as well as group sales by product types.
Database schema:
CREATE TABLE Customer ( CustomerID INTEGER PRIMARY KEY AUTOINCREMENT, FirstName TEXT, LastName TEXT, Email TEXT, Phone TEXT, Address TEXT, RegistrationDate DATE ); CREATE TABLE OrderDetails ( OrderDetailID INTEGER PRIMARY KEY AUTOINCREMENT, OrderID INTEGER, ProductID INTEGER, Quantity INTEGER, PriceAtTimeOfPurchase REAL, FOREIGN KEY (OrderID) REFERENCES Orders(OrderID), -- Updated reference FOREIGN KEY (ProductID) REFERENCES Product(ProductID) ); CREATE TABLE Orders ( OrderID INTEGER PRIMARY KEY AUTOINCREMENT, CustomerID INTEGER, OrderDate DATE, Status TEXT, FOREIGN KEY (CustomerID) REFERENCES Customer(CustomerID) ); CREATE TABLE Product ( ProductID INTEGER PRIMARY KEY AUTOINCREMENT, ProductName TEXT, MetalType TEXT, Form TEXT, Weight REAL, Purity REAL, StockQuantity INTEGER, PricePerUnit REAL ); CREATE TABLE Supplier ( SupplierID INTEGER PRIMARY KEY AUTOINCREMENT, SupplierName TEXT, Contact TEXT, Email TEXT, Phone TEXT ); CREATE TABLE Supply ( SupplyID INTEGER PRIMARY KEY AUTOINCREMENT, SupplierID INTEGER, ProductID INTEGER, SupplyDate DATE, Quantity INTEGER, PricePerUnit REAL, FOREIGN KEY (SupplierID) REFERENCES Supplier(SupplierID), FOREIGN KEY (ProductID) REFERENCES Product(ProductID).