
Introduction
As classifying images into categories is a ubiquitous task occurring in various domains, a need for a machine learning pipeline which can accommodate for new categories is easy to justify. In particular, common general requirements are to filter out low-quality (blurred, low contrast etc.) images, and to speed up the learning of new categories if image quality is sufficient. The task of repurposing a trained model for a different (yet related) task is known as transfer learning. In this blog post, resulting from a joint work with Aigiz Kunafin (Data Scientist at TIMETOACT GROUP Austria), we compare several image classification models from the transfer learning perspective.
Assessment dataset
Our starting point is the task of vehicle classification, based on the well-known kaggle dataset from Tampere University. The images vary greatly in shape and size as well as in content. We first only focus on the two classes, namely cars and trucks. The car class contains images of all different angles and almost all motor car types, from antique cars to racing cars. The truck class comprises nearly all truck types one can imagine. Beside “ordinary” trucks as usually seen on the streets, there are images of military, fire, tow, garbage and tank trucks, to name a few. In addition to cars and trucks, we artificially generate a third class to simulate bad image quality. Therefore, we draw a sample of equal size from each class and randomly augment the images (flipping, blurring, grain, motion blur, darkness). Finally, the dataset contains 971 images of each class.

Finding an appropriate classification algorithm
Our approach is now to implement the architectures below in order to find a classification algorithm with high accuracy for our pipeline. After shaping the data to be used by the models, we save 20% of the data as a test set of unseen images for the comparison of shortlisted models. We then use the remaining 80% of the data for training and validation of the models during their training processes, with a 85/15 train-test-split.
Baseline
As the baseline, we choose a standard PyTorch-based learning pipeline with the ResNet50 model, pre-trained on the ImageNet-1k dataset (also referred to as ILSVRC2012) at resolution 224x224. This model comes in handy for trivial image classification tasks, as it is already familiar with everyday objects, including cars and trucks.
Stepwise Classification Pipeline
With this approach we try to split up the multinomial classification task and use two distinct models for binary classification. A first model is trained to detect if the image belongs to the class of bad image quality. If that is not the case, a second model should detect the class of the image (in this case car or truck). This might turn out beneficial, as each model could be specialized in the respective task. In this approach both models are of the same structure as the baseline model, i.e. a ResNet50 model is used that is already familiar with classes for cars and trucks.
🤗-Transformers Models
“Hugging Face” Transformers is an API that provides state-of-the-art pre-trained models for machine learning as well as a very user-friendly way of implementation. Once the data is in an appropriate folder structure using only one code chunk to specify all necessary model parameters, the API downloads, trains and saves the classification model automatically. In the following we will test the three most liked image classification models on the API: a ViT from Google, a DeiT from Facebook and a DiT from Microsoft. The vision transformer (ViT) from Google is the currently by far most downloaded pre-trained image classification model on the Hugging Face (HF) plattform, being pre-trained on ImageNet-21k and fine-tuned on ImageNet-1k. This model type is in contrast to the above mentioned approaches, as the ResNet50 model is a Convolutional Neural Network (like commonly used for these tasks). Vision transformers, however, might have the capability to overtake CNNs in computer vision tasks in the near future, as several sources speculate and show [1].
Results
Below you can see the classification performance of the different models on a yet unseen test set. As we trained all models on Google Colab, training time might not be fully comparable as processing power depends on current availability.
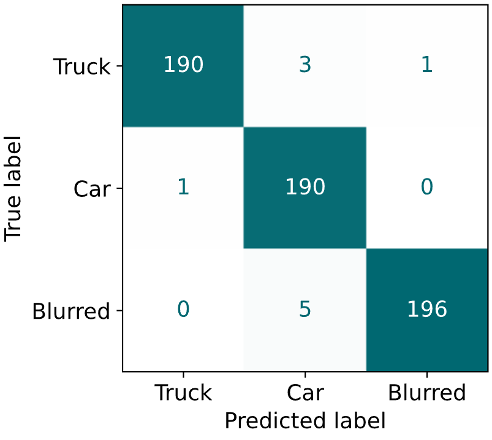
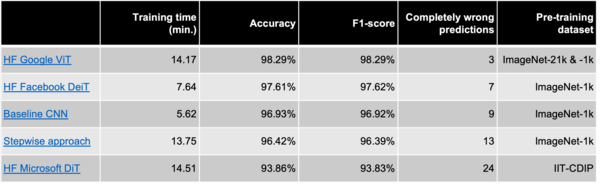
Overall, the evaluation metrics are very high, which is probably partly due to the fact that the models were already pre-trained to detect several types of cars and trucks. Nonetheless, it turns out that the HF models show best performance not only throughout all evaluation metrics but also in a qualitative analysis. Here, we manually check all mispredicted images to see if the model failed miserably or the wrong prediction was due to an ambiguous test image. Taking this into account, especially the performance of the pre-trained Google ViT Model from HF is outstanding as it made almost no obvious mistakes (also check the confusion matrix of this model on the right). However, training two separate models for each classification step (“stepwise approach”) turned out to worsen performance compared to the baseline.
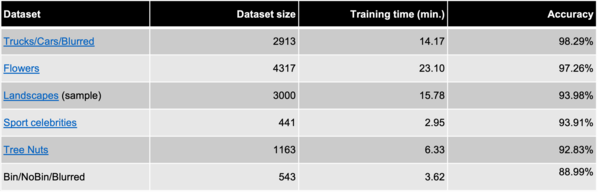
As the HF ViT model from Google performs best and is also very simple to implement, we will now test the respective training pipeline on datasets of other domains. At first, we try out a dataset with images of bad quality as well as images containing garbage bins or not. Checking the results we can see that the newly trained model also works very well for this dataset, achieving an accuracy of close to 90%. Using other datasets from different domains and with multiple classes, we consistently reach accuracy measures above 90% as you can see in the table below.
Validation of Google ViT model
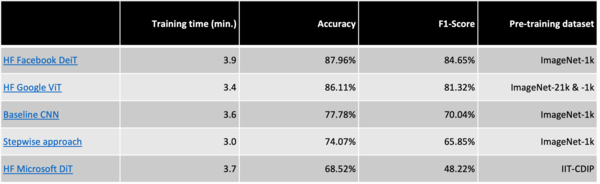
As the HF Google ViT model performed worse for the garbage bin dataset, we now wanna check if this model nonetheless is superior to the other algorithms. We thus train the models from before once again but now on this garbage bin dataset and compare the results. Here we can see that actually the DeiT model from Facebook performed best with an accuracy of almost 88%. Though, the ViT from Google is nearly as good with an accuracy of 86%. Furthermore, please keep in mind that as the test dataset only contains 108 images, the values should not be compared too strictly.
Conclusion
In the end it is stunning to see how straightforward it is to set up and use a HF Transformers pipeline for image classification while also obtaining excellent performance. Initially used on the classification problem of trucks and cars, we could achieve very high accuracy values by using the very popular HF ViT from Google. This might also be due to the fact that the models were already highly pre-trained for these two classes on ImageNet data and that the training as well as test data was very clean. In addition, it turned out that this pipeline can very easily be fed with new data from other domains while maintaining very good performance. However, depending on the concrete image classification problem, other approaches might perform better.
For sure there are almost endless further possible approaches one could try out. Provided one has appropriately labeled data it might be feasible, for example, to first use a basic classifier to check the image quality and then use an object detection model as a classifier, which tries to find the actual object in the image. Additionally, there are many other pre-trained models and classification techniques one could try out. The vision transformer model from the HF API, however, already sets a very high standard. It promises good performance in different domains while needing little training due to pre-training on the ImageNet dataset. Thus, this pipeline can be used as a first point of call proving to be a fast, simple and accurate image classification technique for a wide range of different use cases.
References:
[1] Cf. https://arxiv.org/pdf/2101.01169.pdf, https://arxiv.org/pdf/2010.11929.pdf,
https://becominghuman.ai/transformers-in-vision-e2e87b739feb,
https://towardsdatascience.com/are-transformers-better-than-cnns-at-image-recognition-ced60ccc7c8

















