Within the framework of our Innovation Incubator, the idea arose to develop some tools to facilitate the post-processing of Event Storming sessions conducted in Miro. These tools should help extract information from event stormings for further analysis. In a previous blog post, we discussed how to extract data from Miro Boards. In this blog post, I will show you which text preparation steps are necessary to be able to analyse sticky notes from event stormings and how this analysis can be carried out with the help of the spaCy library.
Motivation
Possible questions that are worth exploring during the post-processing of Event Storming sessions include:
-
How many domain events/commands etc. were created?
-
How are they distributed across the timeline?
-
Are there domain events that occur several times?
-
What are the main subjects?
-
Who was the most active participant in a specific bounded context?
To address questions like these, it is essential that specific DDD concepts are represented correctly by the sticky notes. Event Storming uses a very specific colour-coded key. We represent domain events with orange sticky notes, while commands are written on blue ones. On the other hand, the verb form is crucial. Domain events are described by a verb in past tense (e.g., “placed order”) and commands, as they represent intention, in imperative (e.g., “send notification”). These conventions sound simple, but once participants are “in the flow”, they sometimes have a hard time sticking to them. Restricting ourselves to domain events for now, that means, that we have to ensure in post-processing
a) that all orange sticky notes contain a past-tense verb and
b) that stickies containing past-tense verbs are orange
Luckily, there are NLP libraries that make the analysis of verb morphology (= the study of the internal structure of verbs, e.g. past tense suffixes such as -ed) easy. In the next section, I will explain how this was done using spaCy.
Analysis of verb morphology using spaCy
The starting point was a pandas data frame with information about colour, creator and the content of the sticky note (see here for an explanation of how to retrieve data from Miro).
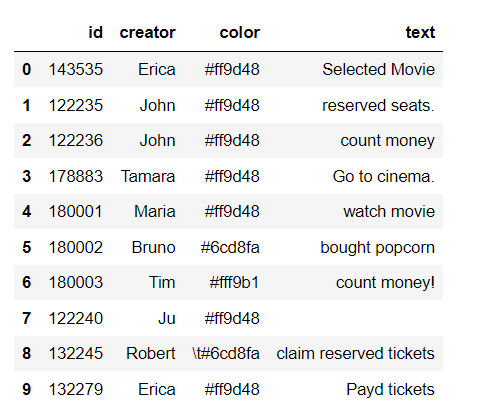
However, before most NLP tasks, it’s necessary to clean up the text data using text preprocessing techniques. For this purpose, we did case normalization and removed punctuation. (here, Python's re module, which provides regular expression matching operations comes in handy).